A process faster than traditional Gradient Descent for training models.
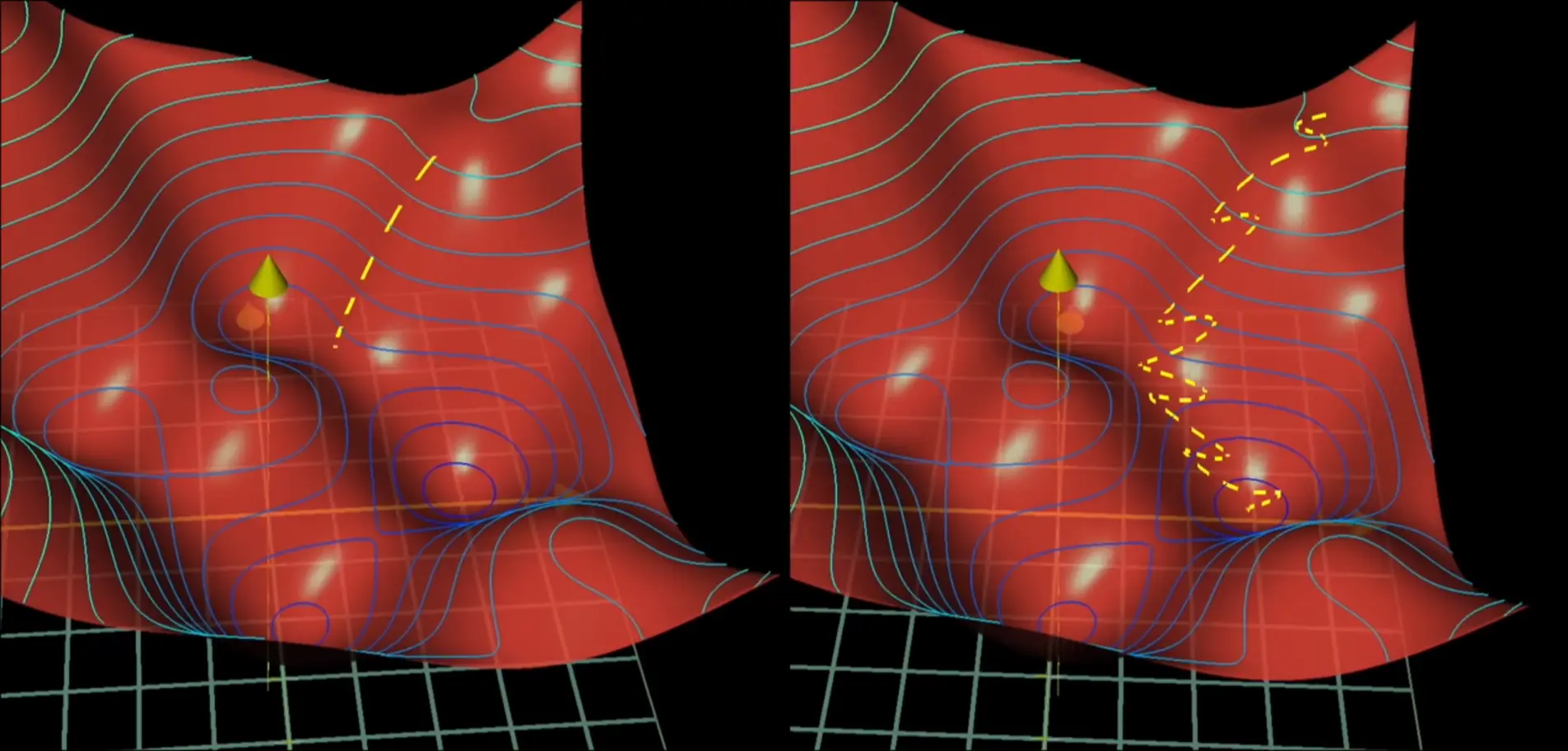
Process
- Divide training data into mini-batches randomly
- Compute the gradient descent step according to this mini batch, instead of data-by-data This allows us to have larger gradient descent steps overall, at the cost of sacrificing accuracy.