This is our first Unsupervised Learning model.
It will stratify our data into amount of clusters.
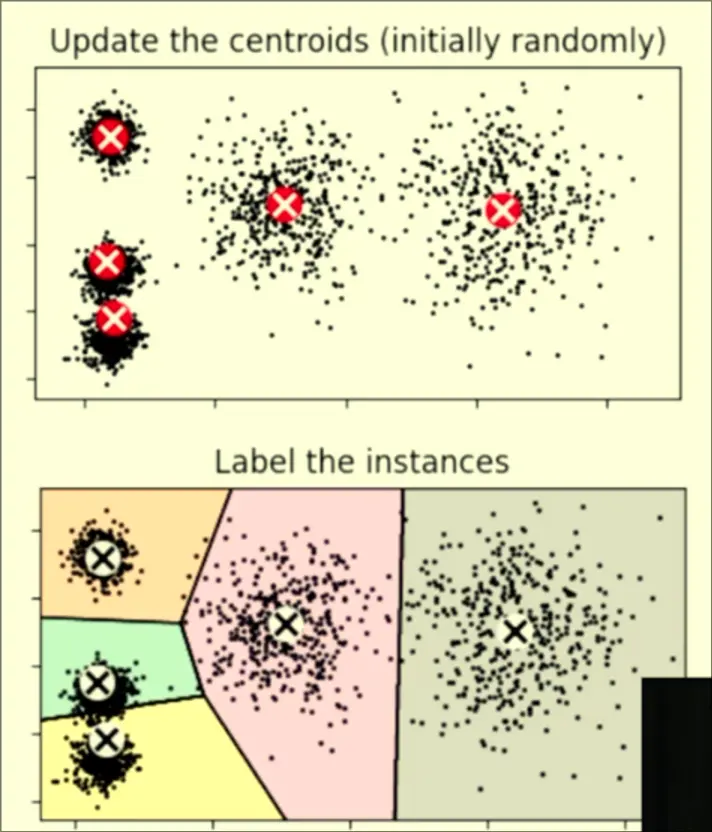
Algorithm
- Given number of clusters, places centroids randomly around the grid
- The centroids should be the exact centers of their clusters. Every datapoint checks which cluster is nearest, and is added into its cluster
- Delete the centroid we already have and place it in the centre of all the points so that the centroid is actually in the center.
- Repeat until there are no more changes