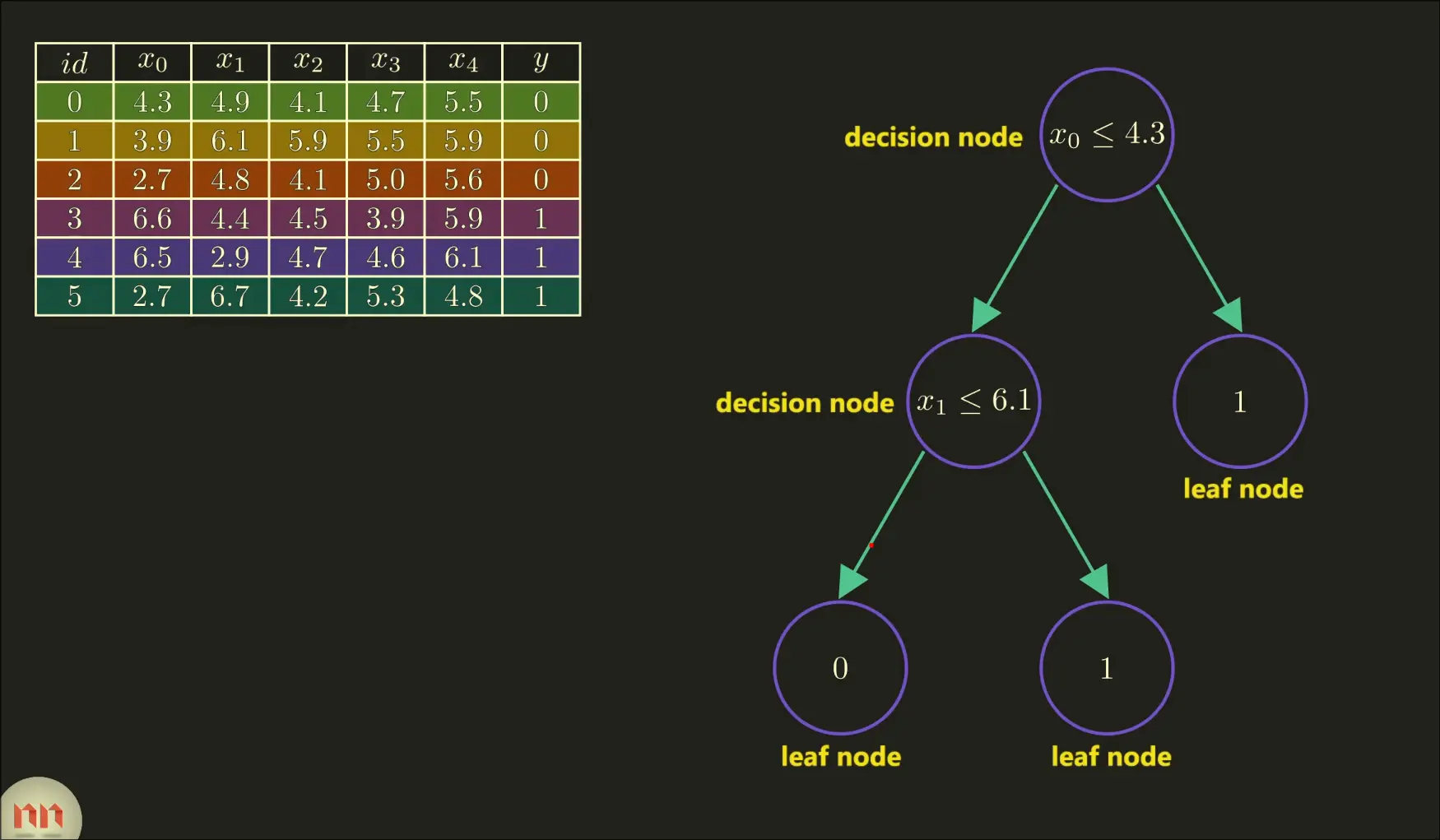
Trees that recursively split the data into subsets based off of features. Flaws They are highly sensitive on training data