A type of Recurrent Neural Networks that is designed to prevent the Vanishing and Exploding Gradient Problem.
Process
- Nodes no longer have weights and biases
- A state that represents the long-term memory connects all nodes
- A state that represents short-term memory connects all nodes with a weight connecting to each mode
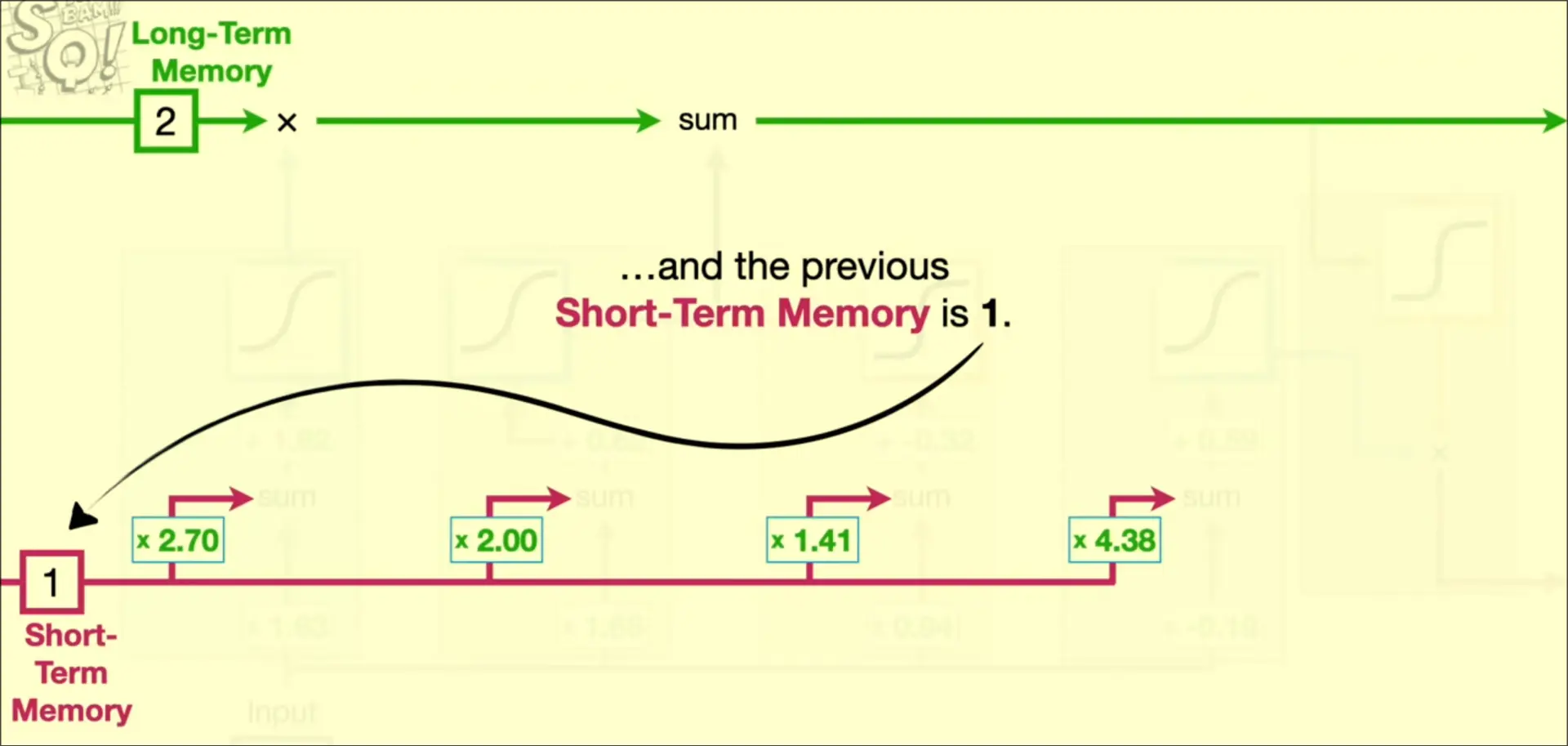
 1. Input is first passed into short-term memory
2. Input is multiplied by weight
3. Short term memory is multipled by another weight then added to the input’s weighted value
4. Passed into activation function
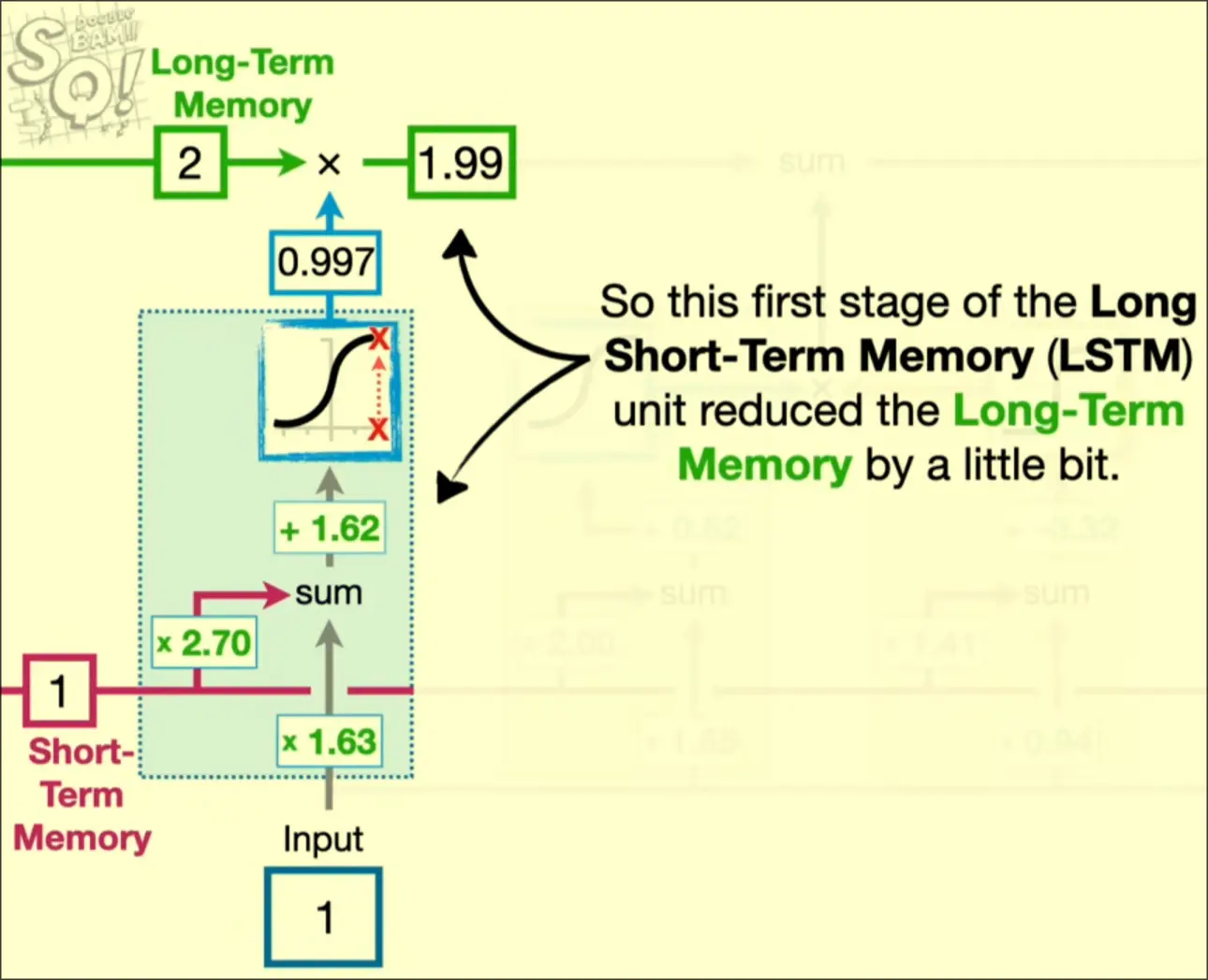
5. Activation function output represents the percentage of the long-term memory to be remembered
1. Input is first passed into short-term memory
2. Input is multiplied by weight
3. Short term memory is multipled by another weight then added to the input’s weighted value
4. Passed into activation function
5. Activation function output represents the percentage of the long-term memory to be remembered