This is my very first datathon, I know a little bit about machine learning
Day 1 - Car Evaluation
- We spun up a simple sklearn random forest classifier
- We tweaked the parameters of random forest classifier to use a higher number of decision tree and reached an accuracy of 99.8%
- Another team member used XGBoost and got 100%
Day 2 - Accident Classification
- We used the same random forest classification model, testing it on the newer with some irrelevant columns dropped that we knew were irrelevant (note we did not go through full data sanitization at this point, we just wanted a trial run to see how well random forest performs)
- Score of 91%-ish
- Testing on SVM, we got 82.5%, so random forest is still the way to go
- Tested for each column to see if removing it would increase accuracy, our final drop and keep column list was this:
df.drop(columns=["ID", "Zipcode", "Country", "Start_Lat", "Start_Lng", "End_Lat", "End_Lng", "Weather_Timestamp", "Street", "City", "Country", "Nautical_Twilight", "Astronomical_Twilight", "Turning_Loop"])
goodcals = ["Severity", "Distance(mi)", "Temperature(F)", "Humidity(%)", "Pressure(in)", "Visibility(mi)", "Wind_Speed(mph)", "Precipitation(in)"]- Ran an outlier script to remove the datapoints that are 3 standard deviations away from the median.
- Switched to LightBGM model, which ran really really really fast!
- Final accuracy was like 96%
Day 3 - Fungi Classification
At this point in time, I started waking up pretty damn late. Like 12pm midday
- We started with a convolutional neural network using MobileNetV2
- Running the model, we got a output that seemed really bad. It was classifying 95% of the testing data as class 2.
- A hint was given on the discord that we should be using feature classifcation
- Created an excalidraw canvas to outline which mushrooms have which key features so that we have a better understanding of which mushrooms have which features
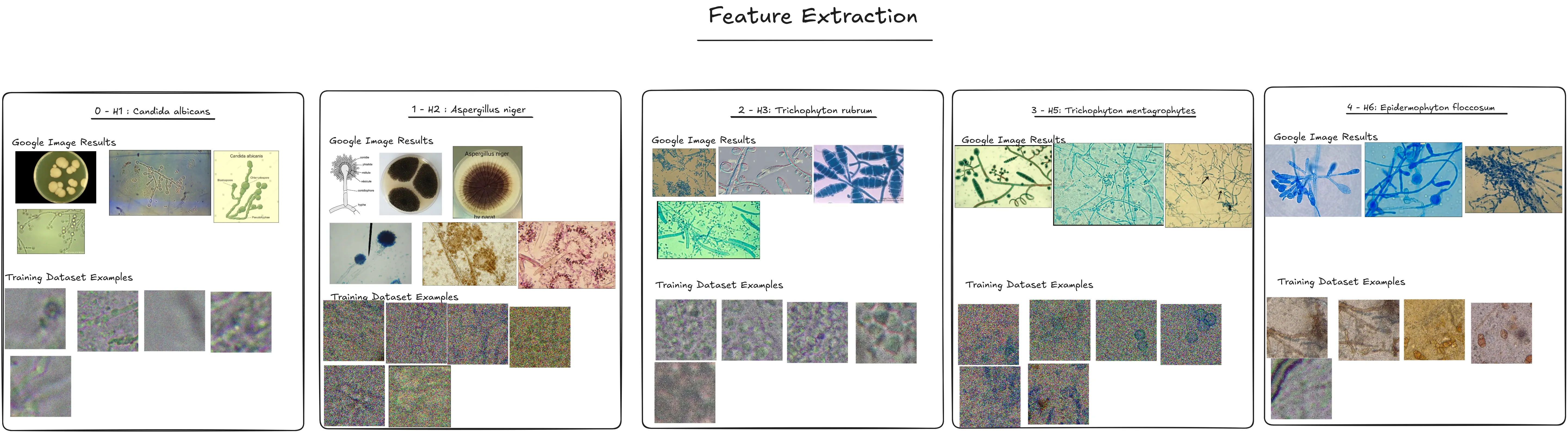 https://excalidraw.com/#json=DOyZdcKVawY2DGbX2nlpV,H6whZTYreGNEgTQDCk6q5w
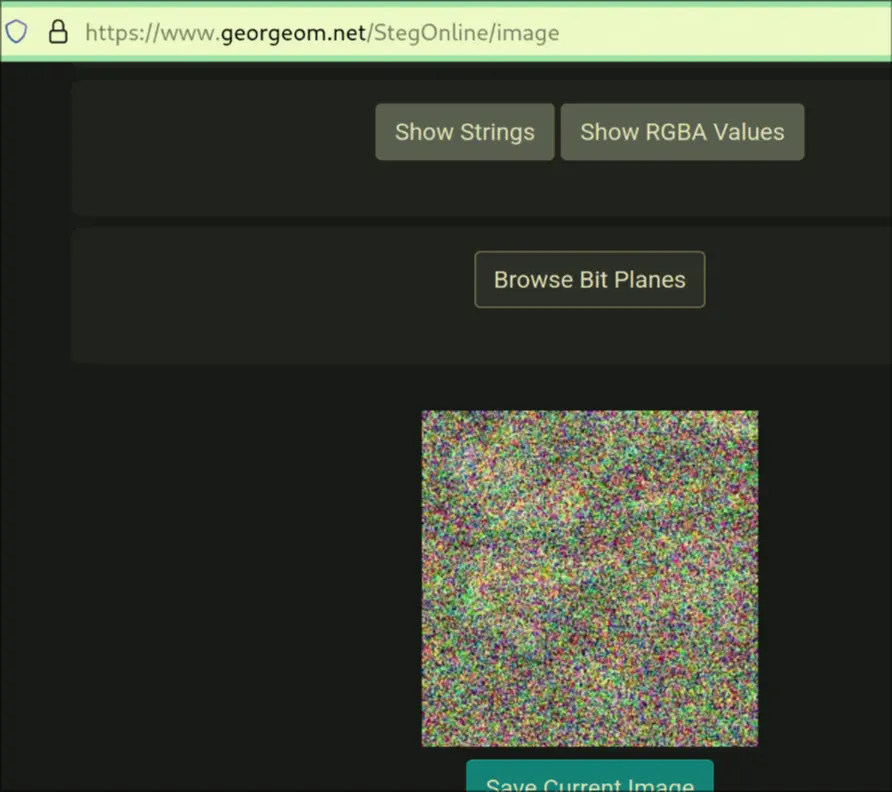
https://excalidraw.com/#json=DOyZdcKVawY2DGbX2nlpV,H6whZTYreGNEgTQDCk6q5w - I also used stegonline, to see if it could better make out some details as the images for category 1 and category 3 are very noisy
- Also, turning images into grayscale helps define details a lot nicer.

- Gaussian blur was suggested, I do like this idea since it makes detail more clear, but we have to make sure that it does not over-blur
- There is a way to get features with OpenCV, here is our code. We get stuff like this:

import pandas as pd
import numpy as np
import cv2 # added for image preprocessing
from keras._tf_keras.keras.preprocessing.image import imagedatagenerator, load_img, img_to_array
from tqdm import tqdm # for progress bar
from sklearn.utils.class_weight import compute_class_weight
from sklearn.metrics import classification_report, confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.preprocessing import labelencoder
def preprocess_image(image_path):
"""loads and preprocesses an image: converting to grayscale, resizing, normalizing, and applying edge detection."""
img = cv2.imread(image_path, cv2.imread_grayscale) # load image in grayscale
img = cv2.resize(img, (224, 224)) # resize image
# apply contrast limited adaptive histogram equalization (clahe)
clahe = cv2.createclahe(cliplimit=2.0, tilegridsize=(8, 8))
img = clahe.apply(img)
# apply gaussian blur to reduce noise
img = cv2.gaussianblur(img, (3, 3), 0)
# extract edges using canny edge detection
edges = cv2.canny(img, threshold1=100, threshold2=200)
cv2.imwrite("test/testimg" + str(i) + ".png", img)
cv2.imwrite("test/edgeimg" + str(i) + ".png", edges)
# load training data
df_train = pd.read_csv("fungi_train.csv")
# preprocess all images
for i, row in df_train.iterrows():
print(row["path"])
preprocess_image(row["path"])- We also tried using Oriented Fast and Rotated BRIEF, but it seems like it finds features that are irrelevant
 With this code:
With this code:
import cv2
import numpy as np
import pandas as pd
import os
from tqdm import tqdm
from sklearn.preprocessing import LabelEncoder
import tensorflow as tf
from tensorflow import keras
from keras._tf_keras.keras.preprocessing.image import ImageDataGenerator, load_img, img_to_array
from sklearn.model_selection import train_test_split
# Load training and test data
df_train = pd.read_csv("fungi_train.csv")
# Initialize ORB detector
orb = cv2.ORB_create(nfeatures=20)
def extract_orb_features(image_path):
"""Extract ORB keypoints and descriptors from an image."""
img = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
if img is None:
return None, None
keypoints, descriptors = orb.detectAndCompute(img, None)
# Draw keypoints on the image
return cv2.drawKeypoints(img, keypoints, None, color=(0, 255, 0), flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
# Display the image with keypoints
counter = 0
# Compute ORB features for training images
for row in tqdm(df_train.itertuples(), total=len(df_train), desc="Extracting ORB Features"):
img_with_keypoints = extract_orb_features(row.Path)
cv2.imwrite("orbedges/features" + str(counter) + ".png", img_with_keypoints)
counter += 1Day 4 - Fungi Preprocessing Again
- I tried a new script, this one will filter out the darkest parts of the image. I also used a generous amount of Gaussian Blur to denoise.
- A read the research paper on this topic linked on the kaggle. https://arxiv.org/pdf/2109.07322.
- The best performing model was:
- ResNet50 with transfer learning
- InceptionV3 without transfer learning
- They used preprocessing techniques that removed images which were irrelevant in content
- Those with black-lens contour

- Those that have no fungal spores
- Those with black-lens contour
- The best performing model was:
- I made a script to MANUALLY sort each image.
import pandas as pd
import numpy as np
import cv2
from PIL import Image, ImageTk # Import PIL for PNG support
from keras._tf_keras.keras.preprocessing.image import ImageDataGenerator, load_img, img_to_array
from sklearn.utils.class_weight import compute_class_weight
from sklearn.metrics import classification_report, confusion_matrix
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder
import tkinter as tk
def highmask(image, weight):
# Calculate threshold
flattened_image = image.flatten()
flattened_image.sort()
threshold_value = max(flattened_image) - (max(flattened_image) - min(flattened_image)) * weight
# Apply threshold
ret, thresholded = cv2.threshold(image, threshold_value, 255, cv2.THRESH_BINARY)
# Apply mask to original image
masked_image = cv2.bitwise_and(image, image, mask=thresholded)
return masked_image
def contrastadd(image):
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8))
return clahe.apply(image)
def canny_edge(image, lower, upper):
tight = cv2.Canny(image, lower, upper)
# show the output Canny edge maps
return tight
def gaussian_blur(image, weight):
return cv2.GaussianBlur(image, (weight, weight), 0)
def preprocess_image(image_path, imgclass):
img = cv2.imread(image_path) # Load image in rgb
img = cv2.GaussianBlur(img, (3, 3), 0)
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # Convert image into grayscale
if imgclass == 0:
img = contrastadd(img)
img = highmask(img, 0.5)
img = gaussian_blur(img, 5)
img = highmask(img, 0.5)
return img
elif imgclass == 1:
# edge detection
img = contrastadd(img)
img = highmask(img, 0.8)
# remove the artifacts
img = gaussian_blur(img, 5)
img = highmask(img, 0.8)
img = gaussian_blur(img, 5)
img = highmask(img, 0.7)
img = gaussian_blur(img, 5)
img = highmask(img, 0.4)
img = gaussian_blur(img, 5)
img = highmask(img, 0.4)
return img
elif imgclass == 2:
img = contrastadd(img)
img = highmask(img,0.5)
img = gaussian_blur(img, 5)
img = highmask(img,0.5)
return img
elif imgclass == 3:
# edge detection
img = contrastadd(img)
img = highmask(img, 0.8)
# remove the artifacts
img = gaussian_blur(img, 5)
img = highmask(img, 0.8)
img = gaussian_blur(img, 5)
img = highmask(img, 0.7)
img = gaussian_blur(img, 5)
img = highmask(img, 0.4)
img = gaussian_blur(img, 5)
img = highmask(img, 0.4)
return img
elif imgclass == 4:
img = contrastadd(img)
img = highmask(img, 0.5)
img = gaussian_blur(img, 5)
img = highmask(img, 0.5)
return img
else:
img = contrastadd(img)
img = highmask(img, 0.5)
img = gaussian_blur(img, 5)
img = highmask(img, 0.5)
return img
# Load training data
df_train = pd.read_csv("fungi_train.csv")
df_test = pd.read_csv("fungi_test.csv")
currentImgPath = ""
def tossfunc(window):
kill_list.append(currentImgPath)
window.destroy()
def keepfunc(window):
window.destroy()
def showandask():
window = tk.Tk()
label = tk.Label(window, text=f"current path: {currentImgPath}")
label.grid(column=0, row=1)
img1 = ImageTk.PhotoImage(Image.open("original.jpg"))
btna = tk.Button(window, image=img1, command=None)
btna.grid(column=0,row=0)
img2 = ImageTk.PhotoImage(Image.open("gaussian_img.jpg"))
btnb = tk.Button(window, image=img2, command=None)
btnb.grid(column=1,row=0)
img3 = ImageTk.PhotoImage(Image.open("bnw_img.jpg"))
btnb = tk.Button(window, image=img3, command=None)
btnb.grid(column=2,row=0)
img4 = ImageTk.PhotoImage(Image.open("high_img.jpg"))
btnb = tk.Button(window, image=img4, command=None)
btnb.grid(column=3,row=0)
img5 = ImageTk.PhotoImage(Image.open("preprocessed_img.jpg"))
btnc = tk.Button(window, image=img5, command=None)
btnc.grid(column=4,row=0)
keep = tk.Button(window, text="keep", command=lambda: keepfunc(window))
keep.grid(column=0, row=2)
toss = tk.Button(window, text="toss", command=lambda : tossfunc(window))
toss.grid(column=1, row=2)
window.mainloop()
kill_list = []
for i, row in df_train.iterrows():
print(row["Path"])
currentImgPath = row["Path"]
original_img = cv2.imread(row["Path"])
gaussian_img = gaussian_blur(original_img, 3)
bnw_img = contrastadd(cv2.cvtColor(gaussian_img, cv2.COLOR_BGR2GRAY))
high_img = highmask(bnw_img, 0.8)
preprocessed_img = preprocess_image(row["Path"], row["ClassId"])
cv2.imwrite("original.jpg", original_img)
cv2.imwrite("gaussian_img.jpg", gaussian_img)
cv2.imwrite("bnw_img.jpg", bnw_img)
cv2.imwrite("high_img.jpg", bnw_img)
cv2.imwrite("preprocessed_img.jpg", preprocessed_img)
showandask()
print(f"kill_list: {kill_list}")
# tkinter promptDay 5 - Fungi Last Time
- Using canny edge detection with the highest-color mask
- Using it with SIFT feature matching:
- I then ran it through the VGG16 model, ensuring that the same layer is cloned 3 times as VGG16 requires a RGB image.
- I spent a few hours installing cuda for tensorflow…
Final Day
- We got like 8th place
Car Eval Solutions
model.fit spammers
- model.fit spammers reviewed the data making histograms for every class
- They tested 5 models:
- Logistic regression
- Decision tree
- KNN
- Random forest
- XGBoost
- They found XGBoost had the best accuracy
- They used n-estimators at 200 and got accuracy of 0.9928
Outliers
- They used random forest
- Check for outliers
- Read each to check the datatype for each
- Check for class imbalance, the data is more biased to unacc
- Made distributions for each feature
- Encoded the categorical features
- ordinal encoding for num doors, etc
- OneHotEncoder for luggage
- Random forest classifier, used cause its general. 200 n-estimators
SGD
- HistGradientBoostingClassifier was used
- Tested for each split, they all got over 90% accuracy
- Ordinal encoding for the data points
Classifying Accidents Solutions
model.fit spammers
- They used XGBoost
- They dropped the columns ID, street, city, country, zipcode, county, weather timestamp, airport code
- They didnt use n-estimators, default is 100
Outliers
- Dropped 5% missing, then tried dropping 20% missin
- They found the mean or mode depending on categorical/numerical variable
- 126 categories → 8 categories for weather, since there is so much
- Boxplot to identify outliers. Keep only the 95% percentile
- Aggregate similar features like traffic & light, turn it into one category
SGD
- Graphed the long at lat, and saw most of them were at united states. lots of accidents at the US
- Drop the columns that seemed uselesslike ID, Zipcode, Weather timestamp, State, Airport Code, Country
- Drop the highly correlated columns like startlat, startlng, windchill, they are very similar to other features
- Classify numerical and categorical features
- XGBoost model
Fungi Predictor
model.fit spammers
- Ran gaussian denoise with 1.0 sigma value
- They used mobilenet V2
SGD
- Used pytorch
- Denoising autoencoder with different denoising for each class.
- Class 0 - weak noise, gaussian filter will do
- Class 1,3 - heavy noise, its uniform noise however, denoise with uniform noise. They know this is true because they simulated the noise in the testing dataset by adding a uniform noise, and it looked similar to the input data
- They used the testing data and noised it back to compare it to existing training data.
- Did a train test split of 80:20
- Used simpleCNN model