DS3 Datathon 2025
This is a development & learning log about my first data science competition organized by UTSC's DS3 club :)
Day 1
This day was spent mostly working on the first challenge, which is making a car evaluation model.
- We spun up a quick SKlearn random forest classifier
- We tweaked parameters of the random forest classifier to use a higher number of decision trees (~100), and we reached an accuracy of 99.8%
- Our team member decided to use XGBoost, and this got our accuracy up to 100%
Day 2
Today was spent working on the second challenge which is car accident classification.
- Drop the irrelevant columns. This is the list of columns we dropped:
df.drop(columns=["ID", "Zipcode", "Country", "Start_Lat", "Start_Lng", "End_Lat", "End_Lng", "Weather_Timestamp", "Street", "City", "Country", "Nautical_Twilight", "Astronomical_Twilight", "Turning_Loop"])
- We tried Support vector machines and got 82.5% accuracy
- We tried Random forest classifier, got 91% accuracy
- Tried LightBGM model, which ran really really fast! - Final accuracy is 96% accuracy
Day 3
At this point in time, I started waking up pretty damn late. Like 12pm midday
- We started with a convolutional neural network using MobileNetV2
- Running the model, we got a output that seemed really bad. It was classifying 95% of the testing data as class 2.
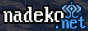
- A hint was given on the discord that we should be using feature classifcation
 4. Created an excalidraw canvas to outline which mushrooms have which key features so that we have a better understanding of which mushrooms have which features
4. Created an excalidraw canvas to outline which mushrooms have which key features so that we have a better understanding of which mushrooms have which features
 https://excalidraw.com/#json=DOyZdcKVawY2DGbX2nlpV,H6whZTYreGNEgTQDCk6q5w
https://excalidraw.com/#json=DOyZdcKVawY2DGbX2nlpV,H6whZTYreGNEgTQDCk6q5w
-
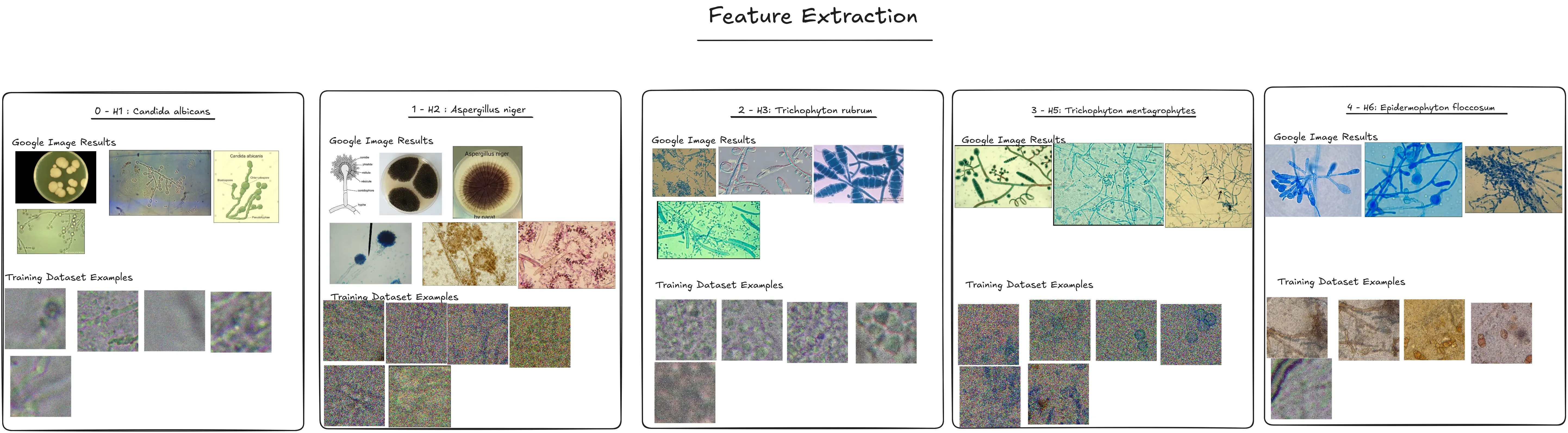
I also used stegonline, to see if it could better make out some details as the images for category 1 and category 3 are very noisy
-
Also, turning images into grayscale helps define details a lot nicer.

-
Gaussian blur was suggested, I do like this idea since it makes detail more clear, but we have to make sure that it does not over-blur
-
There is a way to get features with OpenCV, here is our code. We get stuff like this:

-
We also tried using ORB feature detection, but it seems like it finds features that are irrelevant
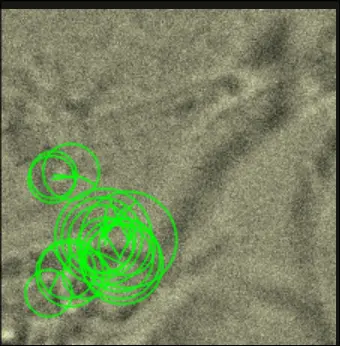
Day 4
Fungi preprocesing again
- I tried a new script, this one will filter out the darkest parts of the image. I also used a generous amount of [[Gaussian Blur]] to denoise.
- A read the research paper on this topic linked on the kaggle. https://arxiv.org/pdf/2109.07322.
- The best performing model was:
- ResNet50 with transfer learning
- InceptionV3 without transfer learning
- They used preprocessing techniques that removed images which were irrelevant in content
- Those with black-lens contour

- Those that have no fungal spores
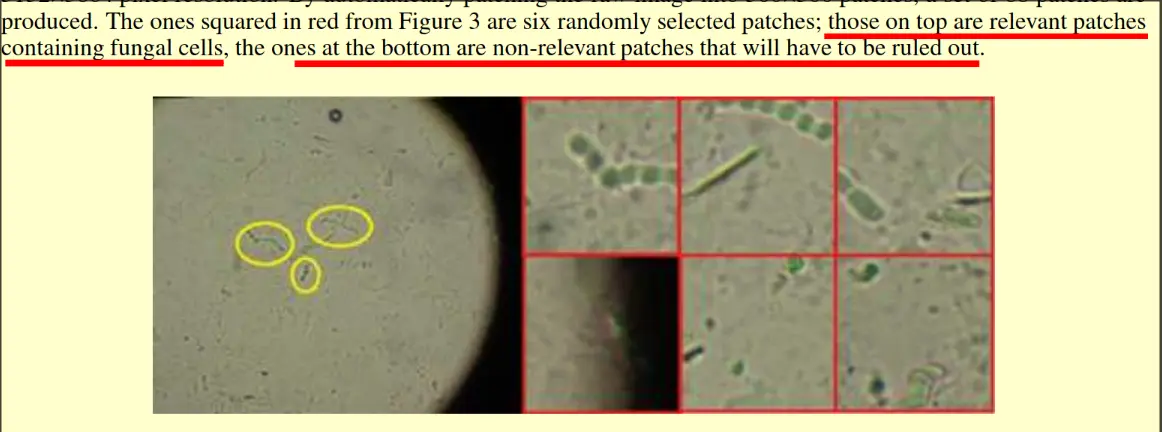
- Those with black-lens contour
- The best performing model was:
Day 4
Fungi preprocesing last time!
- Using canny edge detection with a color mask that filters out only the darkest 20% colors.
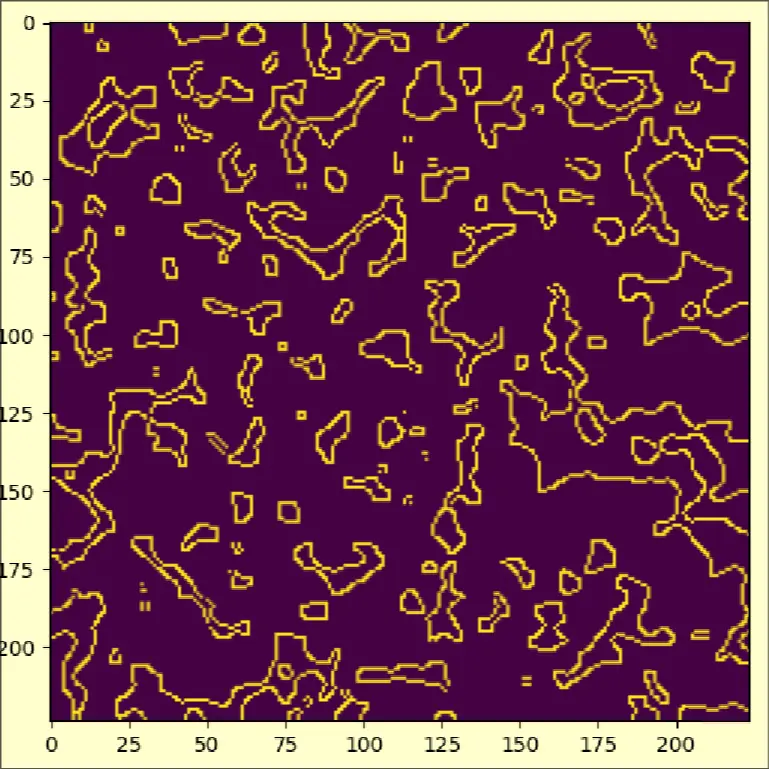
- Using it with SIFT feature matching
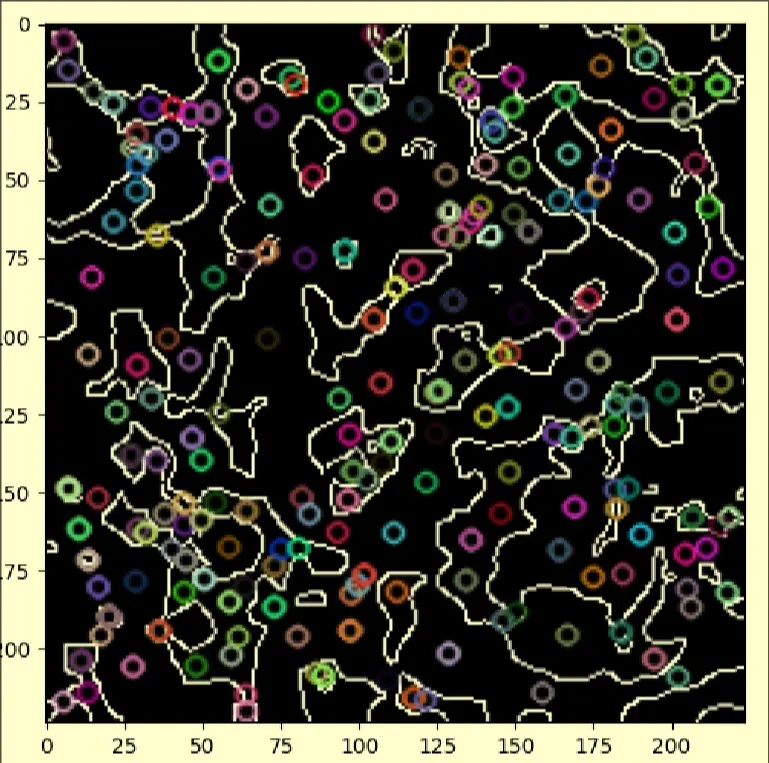
- I then ran it through the VGG16 model, ensuring that the same layer is cloned 3 times as VGG16 requires a RGB image.
- I spent a few hours installing cuda for tensorflow, and then another 2 hours training the model
- Sadly, the preprocessing was not good enough and our model only got ~20% accuracy. Mostly 0's and 2's
Final Day - Lessons
We got like 9th or 10th place overall. Here are the cool things I learned from other teams:
Preprocessing Process
The preprocessing process usually goes:
- Determine features from the dataset
- Graph each feature as a histogram to check of feature imbalance
- Graph the output classes as a histogram to see if the data is biased more to one class
- Ordinal encoding and OneHotEncoder are most useful, use ordinal encodings for the features that seem to have equal weighting, OneHotEncoder for those features that might depend, or be a proportion of another feature
- Random Forest Classifier is the best general-purpose classifier
- HistGradientBoostClassifier is a great model, it was used as an alternative to our XGBoost
- Creating a second neural network model to preprocess images is a viable strategy. One of the main issues we faced for the fungi classifier was the noise. The winning team discovered what noise was being used (uniform noise), Then, it took the testing images (which had no noise), ran it through the uniform noise algorithm, and then trained a neural network to denoise and get the original images.